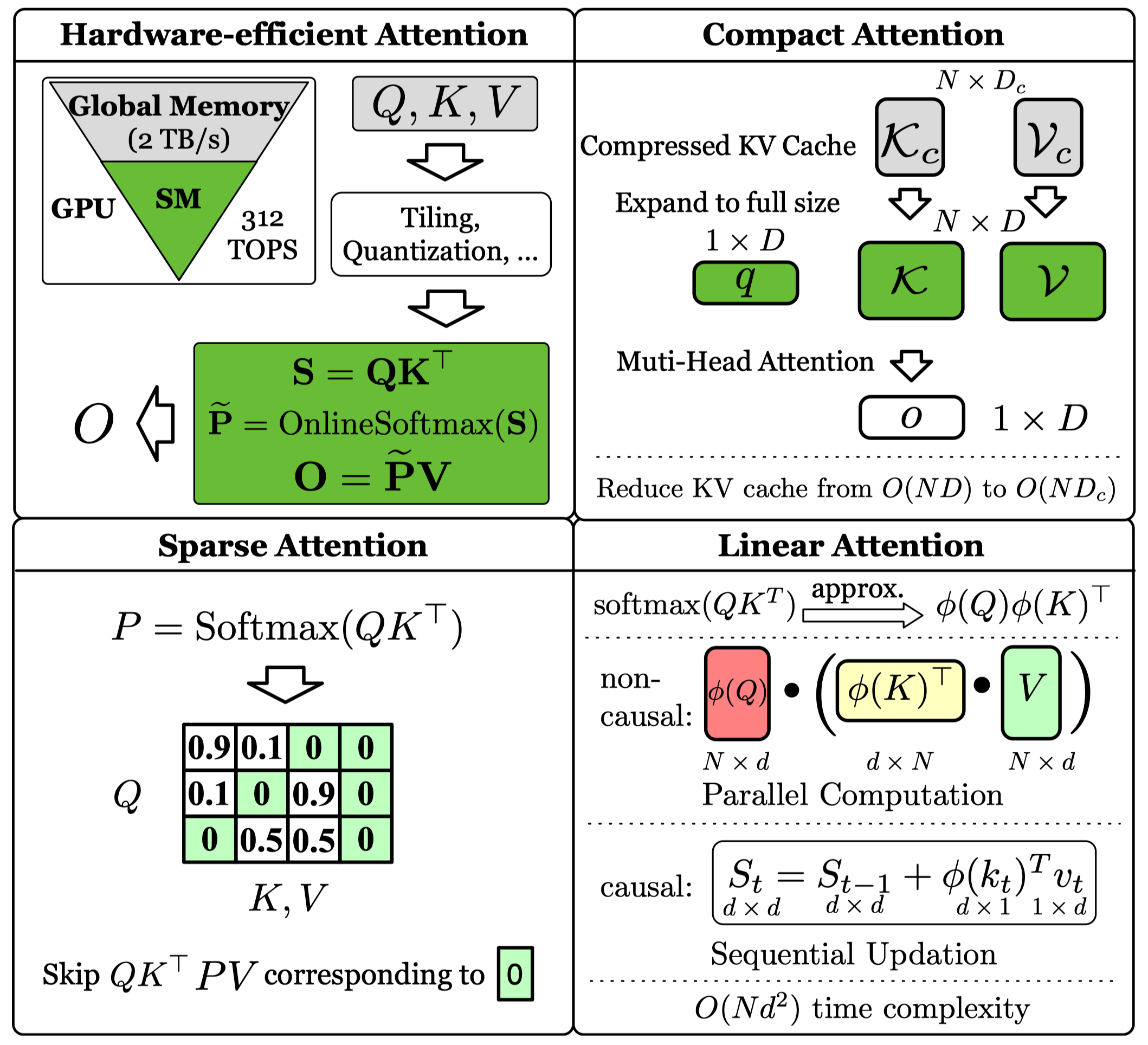
On modern GPUs, an operation's speed is limited by either computation (making it compute-bound) or memory data transfer (making it memory-bound). Hardware-efficient attention methods directly target these bottlenecks by optimizing how computations are performed and data is moved through the GPU's memory hierarchy.
Corresponding to the two stages in LLM inference (prefilling and decoding), Hardware-efficient Attention can be divided into two categories:
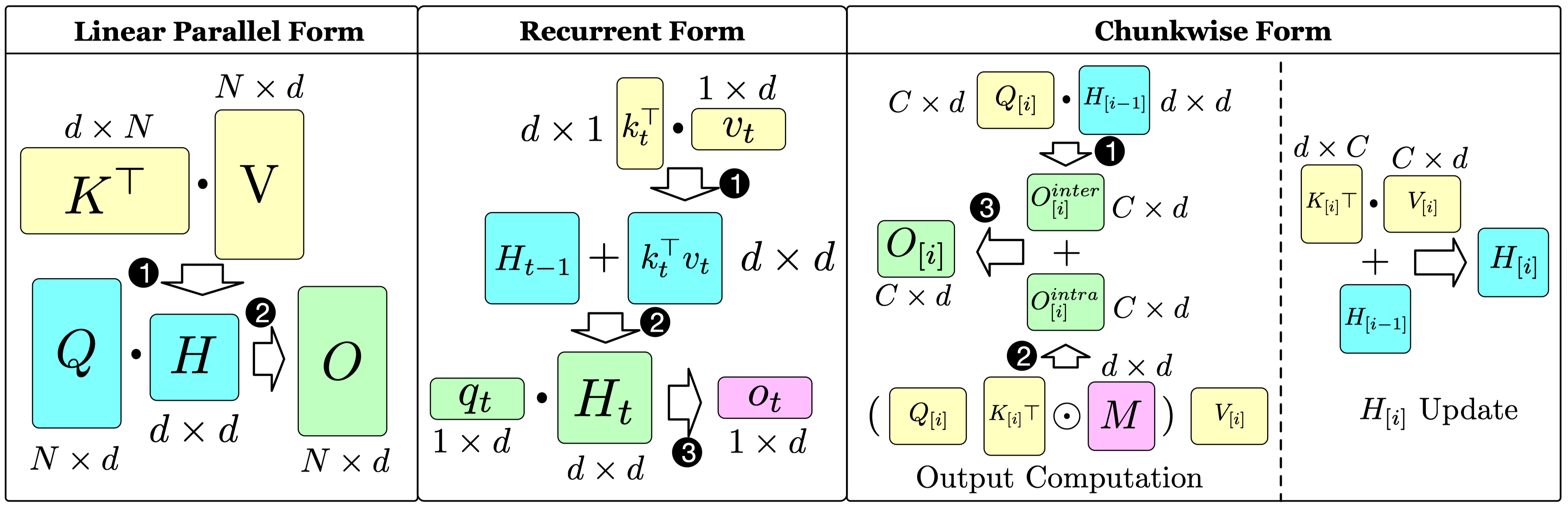
Prefilling methods, inspired by FlashAttention, partition \(Q\), \(K\), and \(V\) into blocks \(\mathbf{Q}_i\), \(\mathbf{K}_i\), \(\mathbf{V}_i\). They compute each output block \(\mathbf{O}_i\) iteratively as follows:
$$
\hat{\mathbf{Q}}, \hat{\mathbf{K}}, \hat{\mathbf{V}} = \Psi(\mathbf{Q}), \Psi(\mathbf{K}), \Theta(\mathbf{V}).
$$
$$
\mathbf{S} = \hat{\mathbf{Q}} \hat{\mathbf{K}}^\top, \quad \hat{\mathbf{P}} = \Theta (\mathrm{softmax}(\mathbf{S})), \quad \mathbf{O} = \hat{\mathbf{P}} \hat{\mathbf{V}},
$$
where \(\Psi(\cdot), \Theta(\cdot)\) are preprocess functions to accelerate computation, e.g., quantization functions.
Decoding methods also partition \(K\) and \(V\) into blocks, but their input \(\mathbf{q}\) is a vector, so the output vector \(\mathbf{o}\) is computed as follows:
$$
\hat{\mathbf{K}}, \hat{\mathbf{V}} = \Psi(\mathbf{K}), \Theta(\mathbf{V}).
$$
$$
\mathbf{s} = \mathbf{q} \hat{\mathbf{K}}^\top, \quad \mathbf{p} = \mathrm{softmax}(\mathbf{s}), \quad \mathbf{o} = \mathbf{p} \hat{\mathbf{V}}.
$$
where \(\Psi(\cdot), \Theta(\cdot)\) are KV cache preprocess functions.
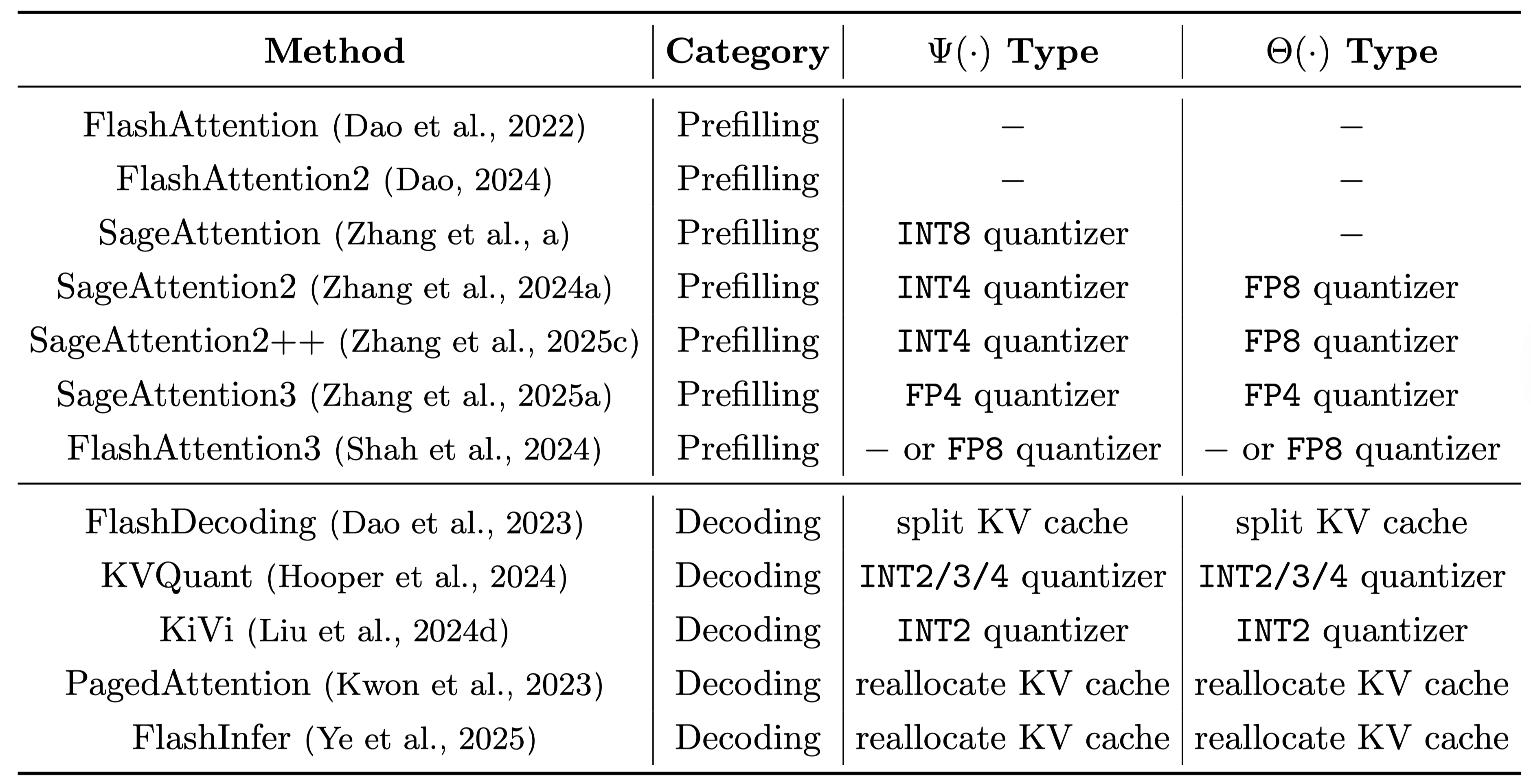
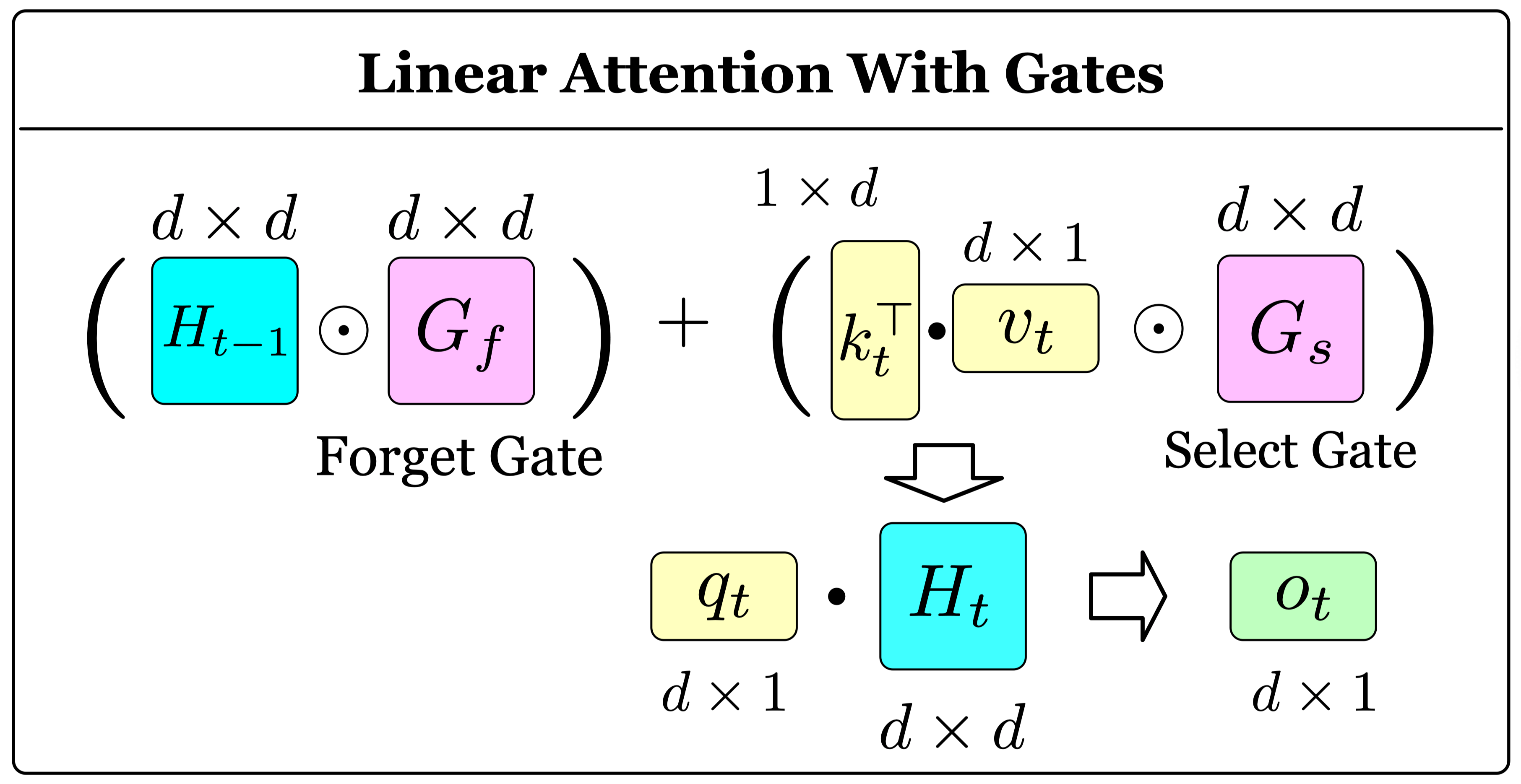
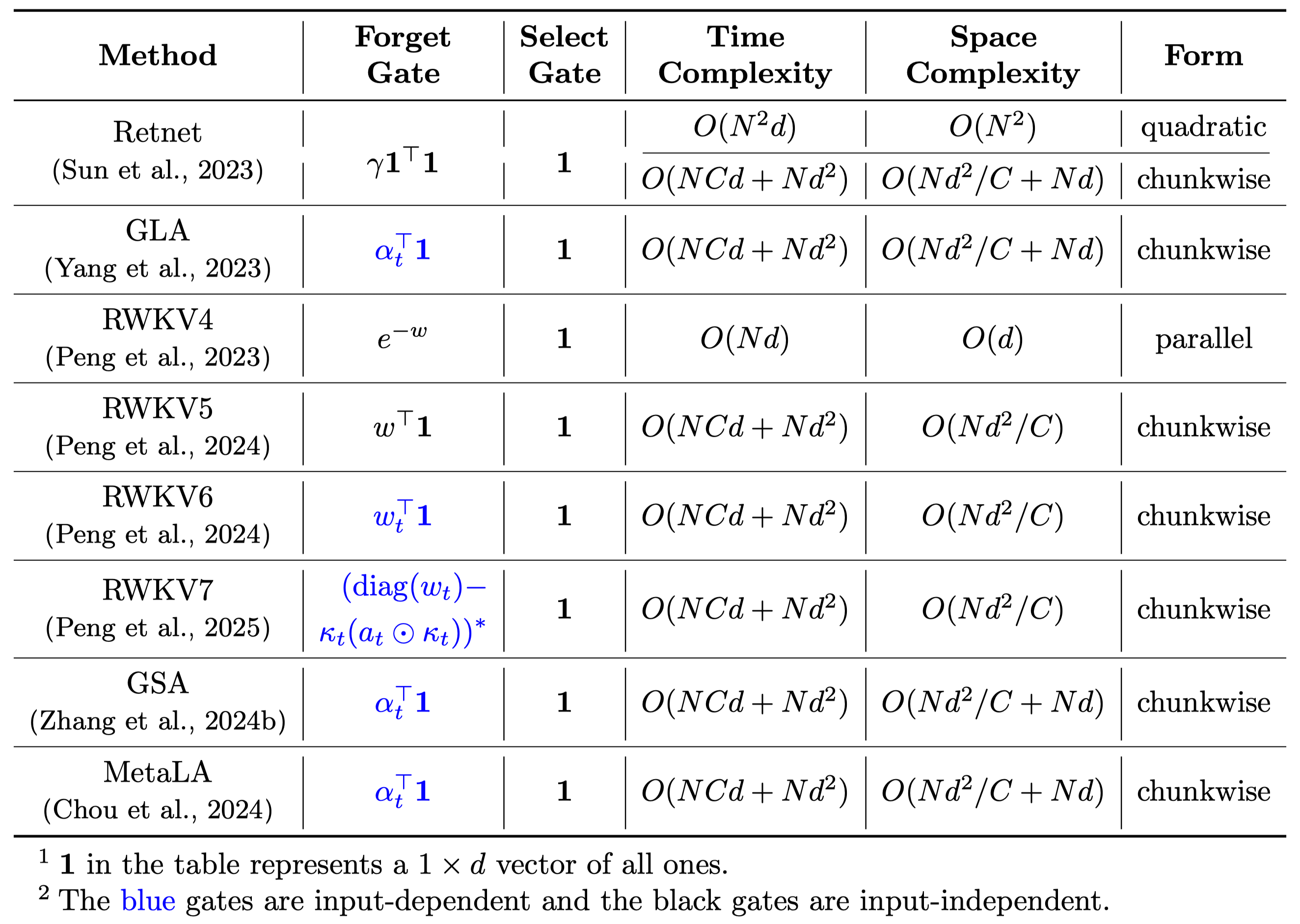
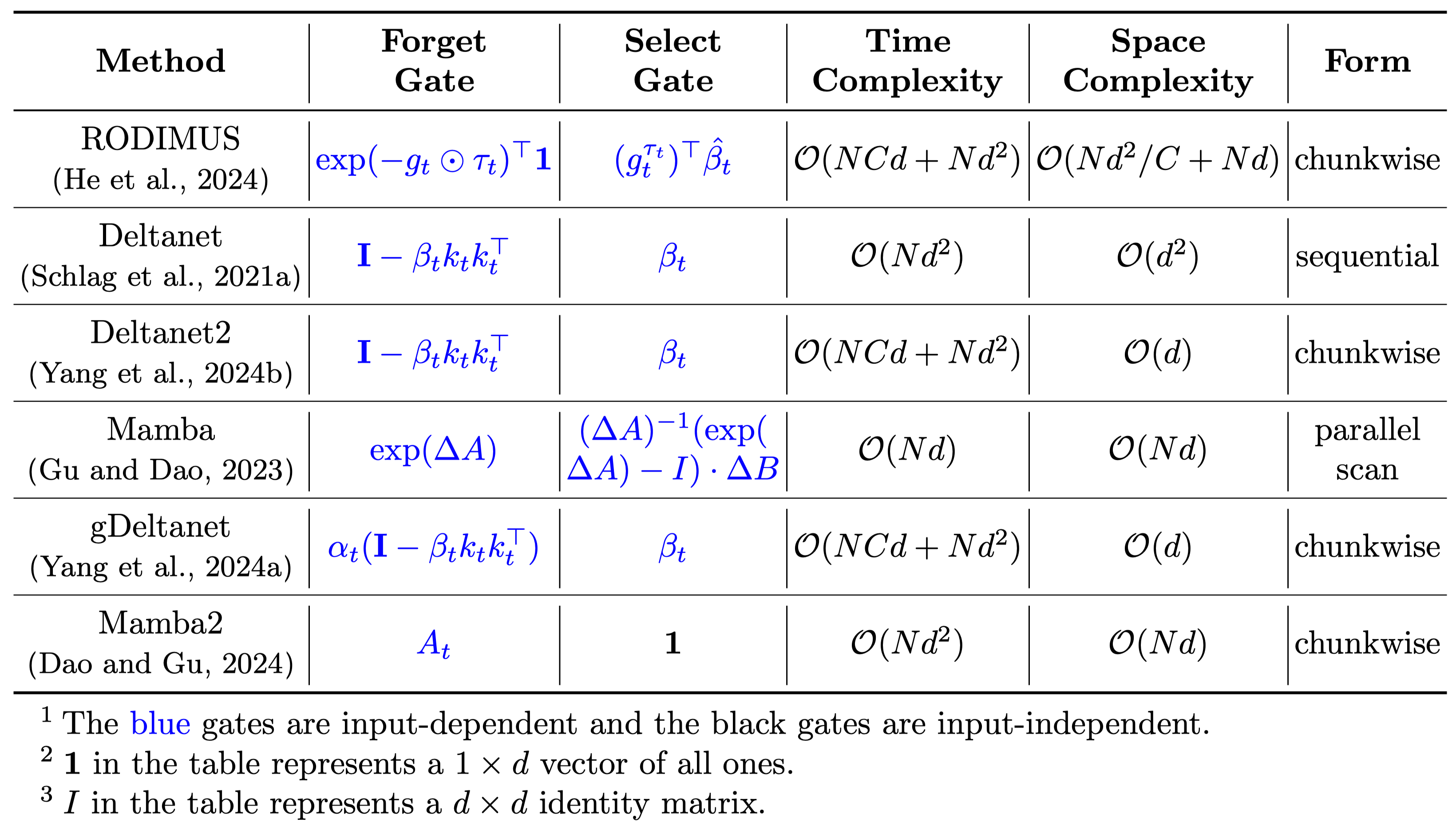
We summarize these hardware-efficient methods in Table 1.
The \(\Psi(\cdot)\) and \(\Theta(\cdot)\) types refer to different pre-processing functions,
such as splitting the KV cache across the GPU's SMs or reallocating it into efficient formats like pages (e.g., PagedAttention) to boost I/O speed.